Processos, threads e co-rotinas em Python
Para explicar o conceito de algoritmo, é normal descrever informalmente como uma sequência de passos para resolver um problema. Ao lidar com concorrência e paralelismo, ainda temos passos a serem seguidos, mas eles não estão mais em ordem necessariamente.
Há várias camadas de abstração – para que o desenvolvedor posso pensar em seus algoritmos como uma sequência de passos – mas na prática muita coisa é executada fora de ordem. Nem mesmo o processador seguem a ordem das instruções, execução out of order é implementado em todas arquiteturas modernas para evitar desperdício de ciclos.
Essas abstrações funcionam muito bem em certos cenários, como é o caso de servidores web e sistemas de banco de dados por exemplo. Entretanto, algumas vezes é necessário lidar diretamente com concorrência e paralelismo.
Não é fácil trabalhar com esses conceitos – é uma mudança fundamental no modelo mental do programador – não surpreende que seja um tópico intimidador para muita gente. Minha ideia é escrever esse post tentando explicar de forma didática, como fazer esse tipo de aplicação em Python.
Conceitos básicos
O que complica (ainda mais) lidar com de problemas de concorrência e paralelismo, é a abundância de conceitos e detalhes de implementação de cada linguagem. Por isso, é bom alinhar alguns conceitos, antes de entrar na implementação.
A ideia é realmente definir o mínimo, tudo bem se a explicação resumida não fizer completo sentido, não acho que seja impeditivo para o entendimento das implementações.
Processos
No contexto de sistemas operacionais, um processo é uma instância do programa sendo executado. Pontos importante sobre processos:
- os processos têm memória isolada, o que está na memória de um processo não pode ser visto por outro;
- o sistema operacional é responsável por escalonar os processos, alternando a execução para que todos tenham algum tempo de execução de acordo com a sua prioridade;
- um processo em execução pode ser interrompido por I/O, entrando em espera quando precisa interagir com algo externo (e.g. rede, armazenamento);
- existe um custo para alternar entre diferentes processos no processador, como limpar os registradores e mudar de pilha.
Threads (kernel threads)
Um processo pode conter uma ou múltiplas threads, são conceitos parecidos, mas com diferenças importantes:
- threads de um mesmo processo podem compartilhar recursos entre si, como conexões de rede e dados na memória;
- o custo de alternar entre threads do mesmo processo é mais baixo que alternar entre diferentes processos;
- dependendo do sistema operacional, o custo de criar e destruir threads é muito mais baixo que processos.
Co-rotinas e tarefas
Os processos e threads são conceitos a nível do sistema operacional, mas é comum as linguagens implementaram algo similar e mais enxuto no próprio runtime. O Python tem as co-rotinas e tarefas, são mais leves para criar/destruir que threads e executadas de forma cooperativa ao invés de preemptiva.
As implementações diferem entre linguagens, as ideias e estratégias discutidas nesse post não se aplicam as co-rotinas de outras linguagens necessariamente.
GIL (Global Interpreter Lock)
A implementação padrão do Python usa o GIL (Global Interpreter Lock), que não permite a execução paralela de threads de um mesmo processo. A presença do GIL simplifica o desenvolvimento da linguagem, mas impede o paralelismo de processamento a nível de thread.
A proposta de deixar o GIL opcional foi aceita, será possível desabilita-ló no Python 3.13. É necessário esperar para ver como será a migração do ecossistema, mas imagino que as limitações de paralelismo serão realidade por muito tempo ainda.
Paralelismo de dados
Raramente é simples transformar um problema sequencial em paralelizável, muitas vezes é simplesmente impossível. Uma estratégia alternativa é aplicar o paralelismo de dados, que consiste em dividir a entrada e combinar os resultados posteriormente.
Um candidato ideal para essa estratégia, é o script que utilizei em outro post para gerar uma massa de dados aleatória, simulando a saída de um modelo de machine learning. Abaixo, a função que gera uma base de amostra:
def generate(self, num_rows: int) -> pd.DataFrame:
df = pd.DataFrame(
{
**{"id_client": [str(uuid.uuid4()) for _ in range(num_rows)]},
**{f"class_{c}": np.random.uniform(size=num_rows)
for c in range(self.num_classes)}
}
)
df.to_parquet(f"{self.path}/{num_rows}-{uuid.uuid4()}.parquet")
A estratégia mais simples para paralelizar esse processo, é executar essa função múltiplas vezes de forma independente: podemos executar a função para gerar \(n\) amostras ou executar \(k\) vezes gerando \(n/k\) amostras por execução, é o mesmo resultado em termos de funcionalidade.
Um dos jeitos mais simples de aplicar paralelismo de dados, é utilizando a ideia de piscina de threads. A “piscina” é um conjunto fixo de threads que ficam disponíveis para uso, as tarefas são enfileiradas e entram em processamento quando uma thread fica disponível. Abaixo, uma ilustração dessa estratégia:

Para implementá-la, é necessário separar o problemas em pedaços menores, o que é trivial nesse caso. Basta dividir o total de linhas pelo tamanho desejado para cada batch:
def _build_batches(self, num_rows) -> Iterable[int]:
for _ in range(num_rows//self.batch_size):
yield self.batch_size
remainder = num_rows % self.batch_size
if remainder > 0:
yield remainder
O tamanho do batch não é muito importante, exceto pelo consumo de memória. Cada chamada da função gera um DataFrame com o tamanho do batch, é necessário ter memória suficiente para que todas as threads possam manter o DataFrame em memória simultaneamente.
Com os batches criados – usando a função map de um ThreadPool – generate é chamada para cada item de batches:
def generate_parallel(self,
num_rows: int) -> pd.DataFrame:
batches = self._build_batches(num_rows)
with ThreadPool(os.cpu_count()) as p:
p.map(self.generate, batches)
Essa implementação está tecnicamente correta, mas não faz sentido devido ao GIL. No final, generate_parallel é mais lenta que generate, ja que as threads não podem ser executadas paralelamente e ainda é necessário coordená-las:
NUM_ROWS = 1_000_000
BATCH_SIZE = 5_000
NUM_CLASSES = 10
generator = SampleGenerator(BATCH_SIZE, NUM_CLASSES, "samples")
%timeit generator.generate_parallel(NUM_ROWS)
%timeit generator.generate(NUM_ROWS)
# 4.8 s ± 51.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 3.73 s ± 16.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
A solução para esse caso, é simplesmente trocar o tipo de pool, usando processos ao invés de threads. O código é idêntico, bastando alterar o tipo de contexto utilizado, de ThreadPool para Pool:
def generate_parallel(self,
num_rows: int) -> pd.DataFrame:
batches = self._build_batches(num_rows)
with Pool(os.cpu_count()) as p:
p.map(self.generate, batches)
Usando um processador de 6 núcleos com SMT, criar as amostras é ~ 4,29 vezes mais rápido, trazendo o aumento de desempenho esperado:
NUM_ROWS = 1_000_000
BATCH_SIZE = 5_000
NUM_CLASSES = 10
generator = SampleGenerator(BATCH_SIZE, NUM_CLASSES, "samples")
%timeit generator.generate_parallel(NUM_ROWS)
%timeit generator.generate(NUM_ROWS)
# 873 ms ± 2.23 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
# 3.75 s ± 25.6 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Algumas perguntas surgem com esses resultados. Se é tão simples, usar processos ao invés de threads, por que usar threads? Para que servem as threads, se existe o GIL?
O problema proposto tem características que o tornam perfeitos para ser utilizado em múltiplos processos:
-
pode ser separado e combinado a custo zero, a função recebe apenas um inteiro de entrada e não precisa se comunicar com os demais processos;
-
é um processo que demanda muito processamento e pouca movimentação dados, o GIL anula a utilidade de trabalhar com múltiplas threads.
Nem sempre é o caso, existem cenários em que threads podem ser úteis, como é o caso dos cenários de aplicação descritas como I/O bound.
O cenário “I/O bound”
Muitos problemas do dia-a-dia não são limitados por tempo de processamento, mas por movimentação de dados fora da memória: escrita em banco de dados, comunicação por rede, escrita em storage, postagem em filas, etc. Essas operações são ordens de grandeza mais lentas que o acesso a memória, são nesses cenários que o uso de threads e co-rotinas fazem sentido.
Para ilustrar esse cenário, o problema proposta agora é salvar essas amostras aleatórias em uma tabela no PostgreSQL. Para ter como baseline, as classes DatabaseNaive e LoaderNaive são a uma solução trivial para esse problema:
class DatabaseNaive(Database):
def __init__(self,
connection_url: str,
num_classes: int) -> None:
super().__init__(connection_url, num_classes)
self.conn = psycopg.connect(connection_url)
def save_message(self, prediction: dict):
with self.conn.cursor() as cur:
cur.execute(*self._build_insert(prediction))
self.conn.commit()
class LoaderNaive():
def __init__(self, db: DatabaseNaive) -> None:
self.db = db
def load(self, df: pd.DataFrame):
for _, row in df.iterrows():
self.db.save_message(row.to_dict())
A solução acima salva um registro de cada vez, esperando a escrita no banco de dados, antes de passar para o próximo. Para 100.000 registros, esse processo demora aproximadamente 6 minutos:
%%timeit
NUM_CLASSES = 10
db = DatabaseNaive(CONNECTION_URL, NUM_CLASSES)
db.create_table()
loader = LoaderNaive(db)
loader.load(predictions)
db.close()
# 5min 54s ± 6.42 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
Threads sendo úteis
A estratégia de threads funciona nesse cenário, porque escrever em banco de dados depende muito de I/O, diferente de gerar amostras que é um processo que demanda muito tempo do processador.
Uma preocupação ao lidar com threads, é garantir que os objetos compartilhados sejam thread safety. Nesse caso, o objeto que precisa dessa garantia é a conexão de banco de dados, compartilhado entre as threads.
O conector de PostgreSQL para Python tem a opção de usar o ConnectionPool, que cria uma piscina de conexões disponíveis para serem alocadas. Dessa forma, cada thread pode utilizar uma conexão distinta, o que elimina os possíveis problemas de concorrência (e.g. condição de corrida, corrupção de dados). Para abstrair esse objeto, foi criada uma classe DatabasePool:
class DatabasePool(Database):
def __init__(self,
connection_url: str,
num_classes: int,
num_threads: int) -> None:
self.connection_url = connection_url
self.num_classes = num_classes
self.pool = ConnectionPool(connection_url,
min_size=num_threads)
def create_table(self):
with self.pool.connection() as conn:
self._create_table(conn)
def save_message(self, prediction: dict):
with self.pool.connection() as conn:
with conn.cursor() as cur:
cur.execute(*self._build_insert(prediction))
conn.commit()
Estendendo a implementação LoaderNaive e adicionando a função load_parallel, é possível fazer a carga no banco de dados com múltiplas threads. A função load_parallel separa o DataFrame em pedaços, para serem posteriormente processados pelo método load:
class LoaderMultiThread(LoaderNaive):
def __init__(self,
batch_size: int,
db: DatabasePool,
num_threads: int) -> None:
self.db = db
self.batch_size = batch_size
self.num_threads = num_threads
def load_parallel(self, df: pd.DataFrame):
dfs = self._make_slices(df)
with ThreadPool(self.num_threads) as p:
p.map(self.load, dfs)
Diferentemente de gerar as amostras, nesse problema existe um ganho de desempenho com o uso de threads, o processo é executado em cerca de 1 minuto e 30 segundos ao invés de 6 minutos.
%%timeit
NUM_THREADS = 48
BATCH_SIZE = 1_000
db = DatabasePool(CONNECTION_URL, NUM_CLASSES, NUM_THREADS)
db.create_table()
loader = LoaderMultiThread(BATCH_SIZE, db, NUM_THREADS)
loader.load_parallel(predictions)
db.close()
# 1min 32s ± 14.4 s per loop (mean ± std. dev. of 7 runs, 1 loop each)
O ganho desse desempenho não veio do aumento de paralelismo, mas de possibilitar concorrência: quando uma thread precisa aguardar o retorno do banco de dados e fica bloqueada, o sistema operacional alterna para executar outra thread.
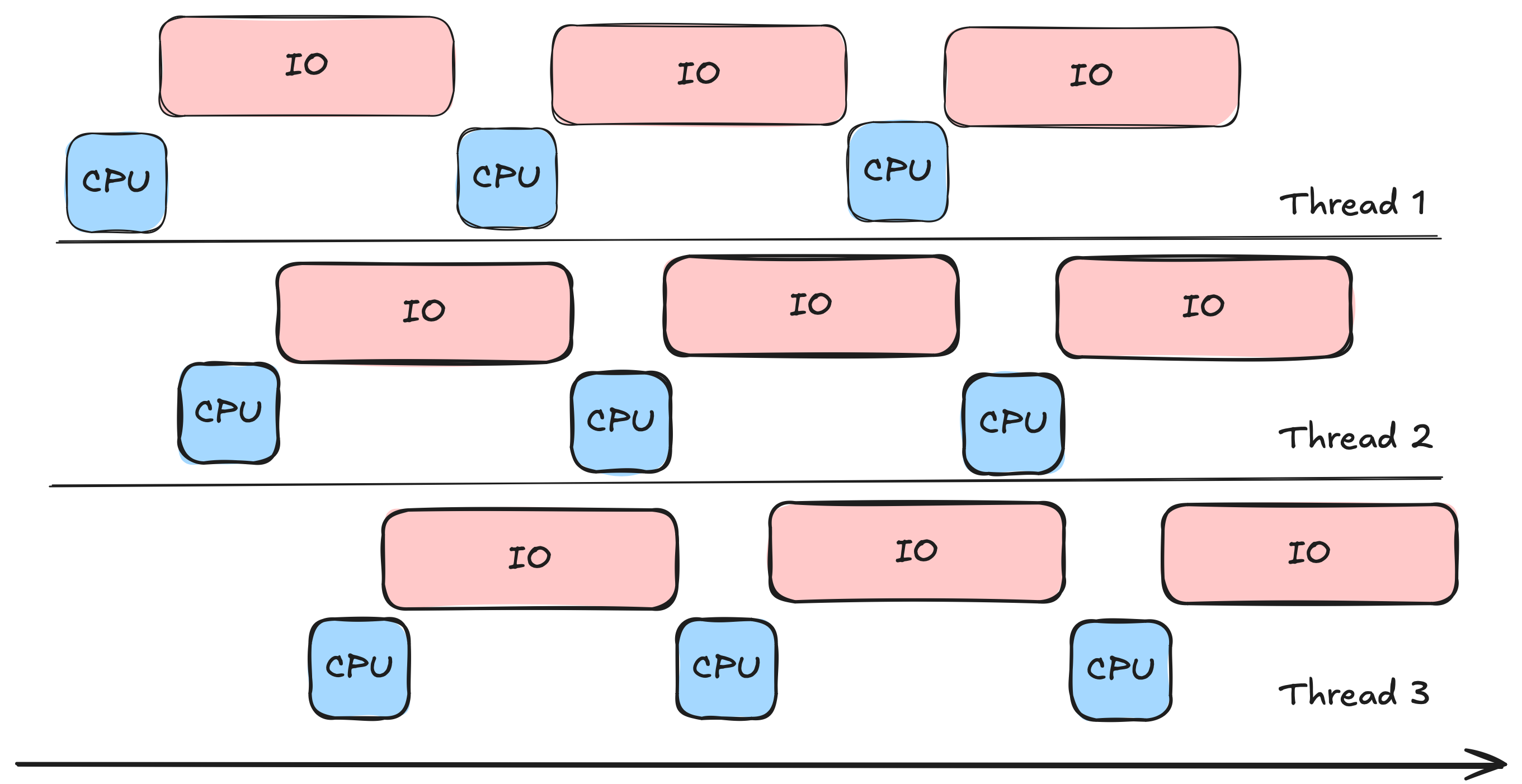
Por que usei 48 threads? É difícil estimar esse número porque tem muitas variáveis: performance do banco de dados, latência de rede, operações concorrentes, etc. A estratégia foi experimentar diversos valores, portanto esse valor só vale para esse cenário.
Apesar de ser efetivo usar threads, essa estratégia faz mais sentido quando não é possível usar co-rotinas e tarefas. Usar interrupções para escalonar as threads talvez não seja o melhor cenário, além de envolver decisões complicadas como escolher o número ideal de threads.
Co-rotinas: mais simples e rápido
O pyscopg implementa comunicação assíncrona com asyncio, que é um jeito mais elegante e nativo de resolver o problema da concorrência. O asyncio tem vários conceitos como tarefas, corotinas, etc – eu mesmo tenho uma compreensão superficial – então recomendo a documentação e outros materiais, caso o leitor queira entender melhor o que está sendo feito.
Para esse cenário, tentei manter a interface de uso o mais parecido possível com a versão síncrona, mas usando a implementação assíncrona do psycopg:
class DatabaseAsync(Database):
def __init__(self,
connection_url: str,
num_classes: int) -> None:
self.connection_url = connection_url
self.num_classes = num_classes
def create_table(self):
conn = psycopg.connect(self.connection_url)
self._create_table(conn)
conn.close()
async def get_conn(self):
return await psycopg.AsyncConnection.connect(self.connection_url)
async def save_message(self, conn, prediction: dict):
async with conn.cursor() as cur:
await cur.execute(*self._build_insert(prediction))
await conn.commit()
async def close(self):
await self.get_conn().close()
O LoaderAsync é muito parecido com o LoaderNaive, processando todos os dados de uma vez ao invés de separá-los em batches menores. Ao invés de trabalhar com um número fixo de threads reaproveitáveis, uma tarefa é criada para cada amostra a ser inserida. As tarefas são baratas de criar e destruir, por isso é possível fazer essa implementação mais simples:
class LoaderAsync(LoaderNaive):
def __init__(self,
db: DatabaseAsync) -> None:
self.db = db
async def load_async(self, df: pd.DataFrame):
conn = await self.db.get_conn()
async with conn:
async with asyncio.TaskGroup() as tg:
for _, row in df.iterrows():
tg.create_task(self.db.save_message(conn, row.to_dict()))
O TaskGroup oferece uma abstração similar ao ThreadPool, inicializando as tarefas e esperando o término de todas que foram criadas sob o contexto. Em termos de performance, foi ainda mais rápido que a solução multithread, com tempo de execução próximo de 25 segundos:
db = DatabaseAsync(CONNECTION_URL, NUM_CLASSES)
db.create_table()
loader = LoaderAsync(db)
await loader.load_async(predictions)
A solução continua sujeita ao GIL, os ganhos em relação ao multithread devem ser provenientes do escalonamento colaborativo, provavelmente mais efetivo para o problema. Entretanto, é bom ressaltar que boa parte do ecossistema Python não suporta asyncio, então nem sempre é possível optar por essa estratégia.
Apesar dos ganhos expressivos, estamos utilizando apenas um núcleo do processador. Separando o problema em vários processos – temos uma execução assíncrona menos eficiente, conforme observado nos testes – mas que pode tirar melhor proveito do hardware disponível.
Processos no lugar de Threads
No primeiro exemplo, substituir processos por threads foi uma questão de trocar o contexto de ThreadPool para Pool. Nesse caso, fazer essa mudança gera um erro pouco claro para o usuário:
db = DatabaseNaive(CONNECTION_URL, NUM_CLASSES)
loader = LoaderMultiProcess(BATCH_SIZE, NUM_THREADS, db)
loader.load_parallel(predictions)
db.close()
# TypeError: no default __reduce__ due to non-trivial __cinit__
É comum ter esses erros estranhos ao trabalhar com múltiplos processos, normalmente são devidos à serialização. Lembre-se que os processos têm memória isolada, para compartilhar objetos entre eles, pode ser necessário traduzir em um formato binário transportável. O problema é que muitos objetos não podem ser transformados, uma conexão de banco de dados tem conexões de rede abertas que não podem ser migradas entre processos distintos.
Para lidar com essa limitação, existe um “truque” que consiste em atrasar a criação do objeto complexo. Essa é a diferença da classe DatabaseLazy para DatabaseNaive, o construtor da DatabaseLazy não cria a conexão no construtor:
class DatabaseLazy(Database):
def __init__(self,
connection_url: str,
num_classes: int) -> None:
super().__init__(connection_url, num_classes)
self.conn = None
def _get_conn(self):
if self.conn is None:
self.conn = psycopg.connect(self.connection_url)
return self.conn
def create_table(self):
self._create_table(self._get_conn())
def save_message(self, prediction: dict):
conn = self._get_conn()
with self.conn.cursor() as cur:
cur.execute(*self._build_insert(prediction))
conn.commit()
def close(self):
self._get_conn().close()
A conexão só é criada na primeira chamada de _get_conn, antes disso é um objeto None. A cópia do objeto DatabaseLazy é feita antes dessa primeira chamada, na abertura do Pool:
class LoaderMultiProcess(LoaderNaive):
def __init__(self,
batch_size: int,
num_threads: int,
db: DatabaseLazy) -> None:
self.db = db
self.batch_size = batch_size
self.num_threads = num_threads
def load_parallel(self, df: pd.DataFrame):
dfs = self._make_slices(df)
with Pool(self.num_threads) as p:
p.map(self.load, dfs)
Usando LoaderMultiProcess temos o melhor tempo de execução, ficando abaixo de 10 segundos em média, estamos falando de uma solução ~41,11 vezes mais rápida que a solução inicial:
%%timeit
import os
db_temp = DatabaseNaive(CONNECTION_URL, NUM_CLASSES)
db_temp.create_table()
db_temp.close()
db = DatabaseLazy(CONNECTION_URL, NUM_CLASSES)
loader = LoaderMultiProcess(BATCH_SIZE, NUM_THREADS*(os.cpu_count()//2), db)
loader.load_parallel(predictions)
db.close()
# 8.61 s ± 13.9 ms per loop (mean ± std. dev. of 7 runs, 1 loop each)
Faz sentido explorar essa abordagem quando há muitos núcleos disponíveis e os ganhos do paralelismo sobrepujam a eficiência das co-rotinas. Em outras linguagens, as tarefas normalmente podem ser processadas paralelamente, sem demandar esse trabalho extra.
Para quem tiver curiosidade, os códigos dos experimentos estão nesse repositório.
Alternativas e futuro
A maioria das linguagens foi criada sem pensar em concorrência e execução assíncrona, o que acaba em soluções não ideais para o problema. A presença do GIL no Python, adiciona mais camadas de complexidade para uma questão que já é inerentemente difícil em quase todos os ambientes de desenvolvimento.
A ideia de trabalhar com múltiplos processos é muito parecido com computação distribuída, o que faz o PySpark parecer uma alternativa interessante em um primeiro momento. Uso bastante e gosto quando a solução pode ser escrita em Spark SQL, mas não faz sentido usar exclusivamente para paralelizar código Python devido ao overhead de integração com a JVM.
O Dask parece ser a melhor alternativa, se a ideia é paralelizar código Python e até distribuí-lo. Não tenho experiência com o framework, mas ele ainda é uma abstração complexa para contornar algo que a maioria das linguagens suporta nativamente.
Dado esse cenário, fico ansioso para acompanhar como será a adoção do ecossistema para execução sem o GIL. Existem muitas iniciativas(1, 2 e 3) para acelerar o Python, mas a remoção do GIL depende de uma adoção pelos usuários, frameworks e bibliotecas para vingar.