Engenharia de dados: por que tão díficil?
No trabalho, apareceu a seguinte demanda: enviar predições de machine learning, armazenadas em uma tabela, para uma fila no formato JSON. Uma demanda trivial…até que sejam adicionados requisitos de performance e escalabilidade.
Nem pretendia escrever nada sobre isso, mas esse problema acabou sendo um exemplo didático dos desafios particulares da engenharia de dados. Resolvendo esse problema, é possível passar por muita das dores que é trabalhar com fluxos de dados.
Mockando a entrada
Para começar, devemos gerar uma base de exemplo, idealmente seguindo a distribuição e volumetria dos dados reais. Não é incomum encontrar problemas que só aparecem em produção, pelas características únicas do dado e volumetria.
A saída do modelo, que precisamos enviar para a fila, é uma tabela com o schema abaixo.
root
|-- id_client: string (nullable = true)
|-- class_0: double (nullable = true)
|-- class_1: double (nullable = true)
|-- class_2: double (nullable = true)
...
|-- class_29: double (nullable = true)
O campo id_client identifica o cliente unicamente com um UUID. Os campos com a nomenclatura class_[0-9]+, que estão no intervalo [0,29], representam as probabilidades de cada classe do modelo de machine learning.
Para gerar os dados nesse formato, foi utilizado esse script Python que gera predições aleatórias em um arquivo Parquet. Para esse experimento, foram geradas 60 milhões de predições.
Antes de executar esse script, é necessário definir o tamanho da variável chamada BATCH_SIZE, que vai depender da memória disponível e quantidade de processos utilizados.
NUM_CLASSES = 30
BATCH_SIZE = 2_000_000
NUM_CLIENTS = 60_000_000
PATH = '../resources/inline.parquet'
O batch de de 2 milhões de clientes foi escolhido, considerando que tenho 12 “virtual cores” e aproximadamente 16GB livres de memória. Fazendo alguns testes, foi possível chegar nesse valor, que otimiza o tempo de execução para essa configuração.
Eu poderia ter feito uma solução single-thread, gerando as predições linha a linha, em um arquivo texto. Demoraria muito mais para rodar, mas consumiria pouca memória e não exigiria essa otimização do BATCH_SIZE.
É interessante pensar sobre isso, porque engenharia de dados é muito mais sobre os requisitos não funcionais que funcionais. Entre as duas opções de solução, o papel do engenheiro de dados é entender os requisitos não funcionais para decidir o melhor caminho.
Por exemplo, se esse script for executado no mesmo servidor que uma aplicação transacional online, usar uma solução multi-thread pode gerar problemas de indisponibilidade para a aplicação. Por outro lado, se estamos usando máquina dedicada em nuvem para esse processo, estamos perdendo tempo e dinheiro, ao não estressar ao máximo a memória e o processamento com a solução multi-thread.
Com a base de exemplo gerada, podemos partir para o problema em questão: transformar essas 60 milhões de predições em mensagens JSON.
Como não agrupar as predições
Para enviar essas predições em uma fila, o ideal é agrupá-las em um único payload, para usar menos mensagens e transmitir a mesma informação. As predições podem ser agrupadas aleatoriamente, mas ter uma quantidade fixa de mensagens, que não ultrapasse máximo definido para o payload. Nesse exemplo, iremos utilizar grupos de 10 mensagens.
Para fazer esse agrupamento, é simples: sabendo o total de linhas \(N\) e a quantidade de mensagens por grupo \(K\), precisamos criar \(G\) grupos, sendo \(G=N/K\).
Para distribuir as predições dentro desses grupos, associando um sequencial \(\#N\) para cada mensagem, podemos obter o grupo da linha utilizando o resto da divisão: \(\#N \ mod \ G\).
Em um processo single-thread, é trivial associar um sequencial \(\#N\) para as linhas: basta ler o arquivo linha a linha, incrementar um sequencial a cada iteração e associá-lo a mesma.
Mas nesse processo, vamos usar o Spark como framework de programação distribuída, emulando o cenário real em que esse dado estará armazenado em um storage e será processado por um cluster de máquinas.
No próprio knowledge base da Databricks, é sugerido criar esse sequencial da seguinte forma:
from pyspark.sql.functions import *
from pyspark.sql.window import *
df_with_increasing_id = df.withColumn("monotonically_increasing_id", monotonically_increasing_id())
window = Window.orderBy(col('monotonically_increasing_id'))
df_with_consecutive_increasing_id = df_with_increasing_id.withColumn('increasing_id', row_number().over(window))
Primeiramente, é gerado uma coluna com um identificador crescente e monotônico, mas não contíguo. Com base no identificador criado, usar uma função de janela para criar um identificador sequencial e contíguo.
Solução elegante, mas ao executar esse código, o próprio Spark avisa que pode ser um problema:
WARN WindowExec: No Partition Defined for Window operation! Moving all data to a single partition, this can cause serious performance degradation.
A função de janela envolve ordenar todo o DataFrame, um processo muito custoso em execução distribuída, já que envolve transferir e processar todos os dados em uma única máquina.
Em uma execução single-node, seria demorado ordenar todo o dataset, mas provavelmente funcionaria porque os dados já estão na mesma memória. Em produção, com esse dado distribuído em vários nós de computação, o processo ficaria muito mais lento e poderia incorrer em erros por falta de memória.
Reproduzir um ambiente de execução distribuído é muito complexo, muitas vezes o processo é desenvolvido localmente, gerando erros que só aparecem tardiamente no processo de desenvolvimento.
O argumento de “funciona na minha máquina”, que é motivo de piada entre os programadores, tem menos valor ainda quando se fala de engenharia de dados.
Agrupando com zipWithIndex
Uma alternativa, menos onerosa para resolver esse problema, é utilizar a função zipWithIndex que ordena os registros dentro de suas partições. O problema é que essa função é do objeto RDD, a estrutura de dados distribuída sobre a qual o DataFrame é construído.
Em outras palavras, significa que teremos que usar código procedural ao invés de Spark SQL. Enquanto usamos a API de DataFrame, a linguagem utilizada não impacta na performance do processo, mas o cenário muda quando manipulamos diretamente o RDD.
O Python é a lingua franca do mundo dos dados, mas em cenários que demandam alto desempenho, ele trabalha como a “cola” e não como runtime principal. Ao utilizar PySpark, estamos usando Python para orquestrar o trabalho pesado feito na JVM em Scala.
Abaixo os códigos – em Python e Scala – para a mesma solução: incluir uma coluna sequencial a um DafaFrame utilizando zipWithIndex. Utilizando essas duas implementações, podemos fazer uma comparação de performance entre as duas linguagens.
# Criação de coluna sequencial em Python
def add_sequence_column(df: DataFrame, col: str) -> DataFrame:
return (df
.rdd
.zipWithIndex()
.map(lambda x: Row(**(x[0].asDict() | {col: x[1]})))
.toDF())
// Criação de coluna sequencial em Scala
def add_sequence_column(df: DataFrame,
col: String,
spark: SparkSession) : DataFrame = {
val rdd = df
.rdd
.zipWithIndex()
.map(x => Row.fromSeq(x._1.toSeq ++ Array(x._2)))
val schema = df.schema.add(StructField(col, LongType))
spark.createDataFrame(rdd, schema)
}
A ideia é gerar um DataFrame com as predições agrupadas e serializadas em JSON, prontas para o envio. Ao invés de enviarmos para uma fila, os dados serão salvos em um arquivo Parquet.
// Solução em Scala
val messages_to_send = add_sequence_column(file, "sequential_id", spark)
.withColumn("predict",
struct(file
.schema
.fields
.map(column => col(column.name)): _*))
.withColumn("predict_group", col("sequential_id") % lit(num_groups))
.groupBy(col("predict_group"))
.agg(collect_list("predict").alias("predicts"))
.select(to_json(col("predicts")).alias("predicts"))
messages_to_send
.write
.mode("overwrite")
.parquet("../resources/output_scala.parquet")
# Solução em Python
messages_to_send = (add_sequence_column(file, 'sequential_id')
.withColumn('predict', struct([col(c.name)
for c
in file.schema]))
.withColumn('predict_group', col('sequential_id') % lit(num_groups))
.groupBy(col('predict_group'))
.agg(collect_list('predict').alias('predicts'))
.select(to_json(col("predicts"))))
(messages_to_send
.write
.mode("overwrite")
.parquet("../resources/output_python.parquet"))
Ao avaliar a execução da solução Python, podemos perceber que são necessários mais jobs para executar a parte Python da aplicação.
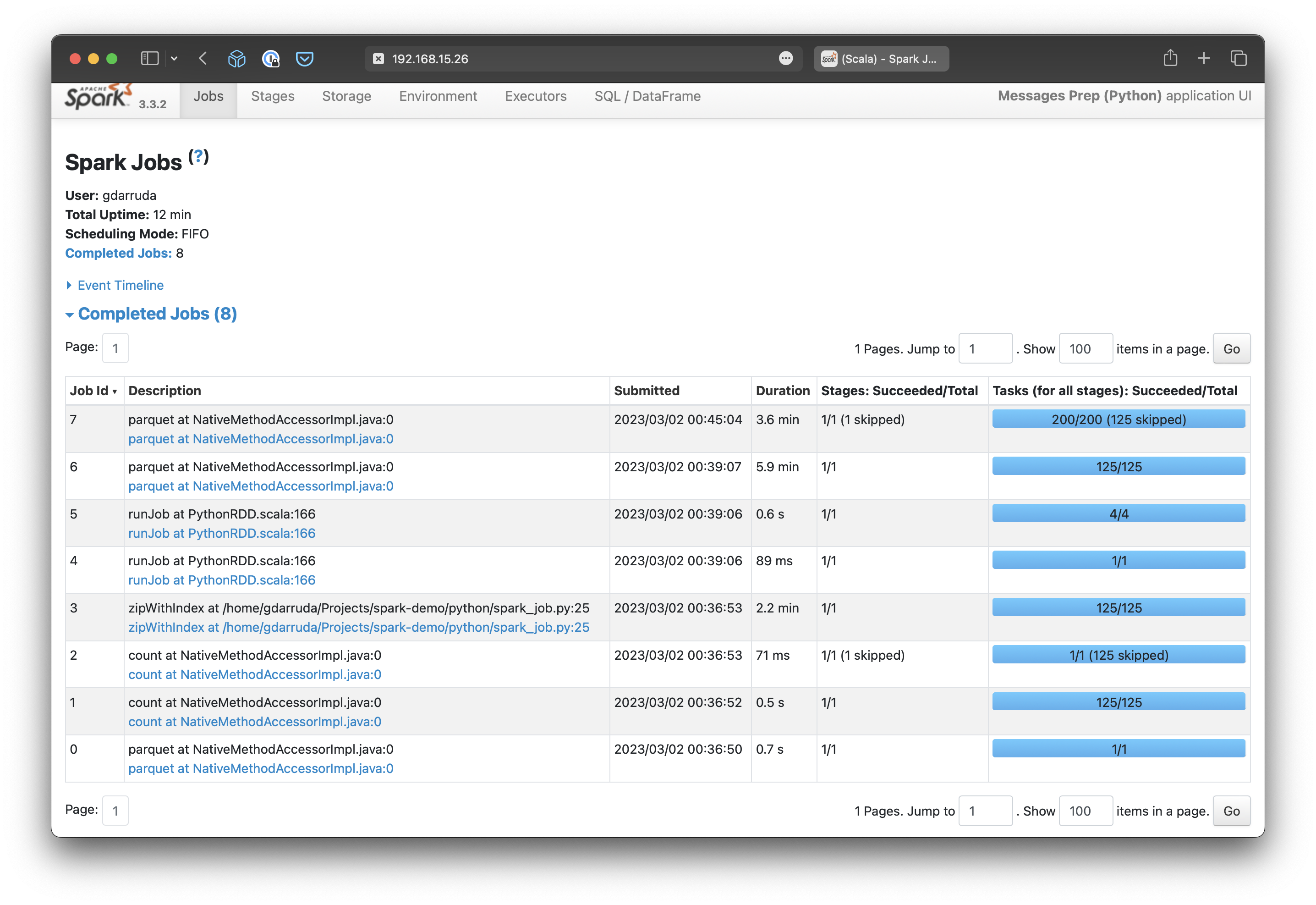
Não são jobs muito demorados, mas os demais jobs demoraram mais também. Talvez, o motivo seja o maior uso de swap, pois enquanto executava percebi que o processo em Python acabava gastando mais memória que o processo em Scala.
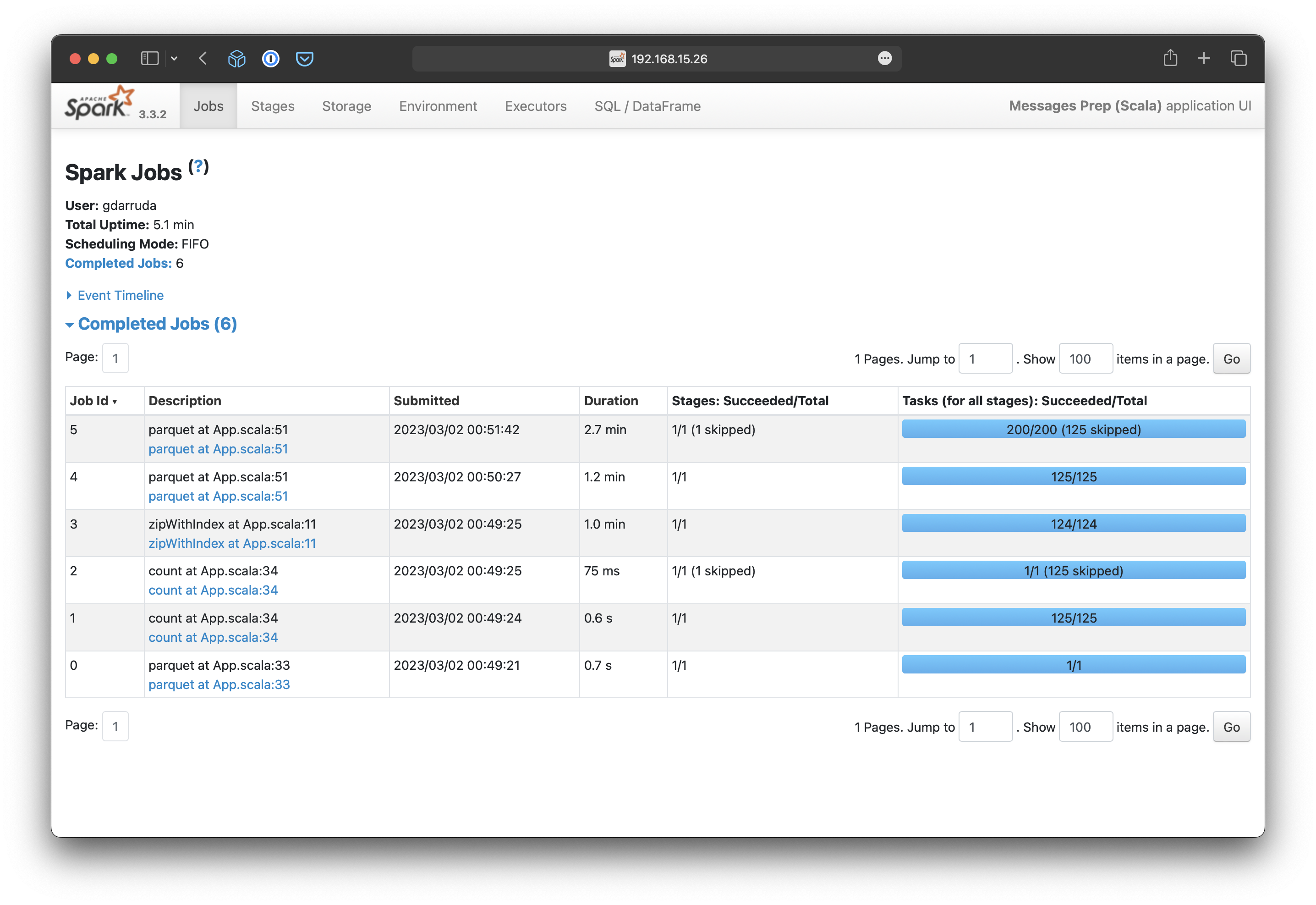
No final, o processo em Python demorou um total de 12 minutos, enquanto o processo em Scala demorou 5 minutos. O processo foi executado localmente, na mesma máquina utilizada para geração do dataset, esses são os relatórios de execução.
Em um cenário com mais memória, a diferença entre as soluções poderia ser menor. Ou maior, se o problema for apenas performance do código Python e não a questão de memória.
Estimar a performance em fluxo de dados é muito complexo, porque além do poder de processamento, é necessário considerar outras variáveis como memória, armazenamento e rede de um ambiente distribuído.
Em um cenário de menos memória, como o apresentado, a velocidade do armazenamento vira um possível gargalo. Por outro lado, se o processo estiver distribuído em muitas máquinas com uma rede lenta, operações de shuffle podem minar completamente o desempenho.
Por isso, é importante que o engenheiro de dados tenha uma noção intuitiva do que está acontecendo internamente nas soluções, para evitar gargalos desnecessários e facilitar o troubleshoot. Em teoria, qualquer engenheiro de software deveria ter essa perspectiva, mas nem sempre é o que ocorre.
No contexto de empresas que precisam se mover com agilidade, é normal priorizar velocidade e manutenabilidade no desenvolvimento em detrimento a performance do software. Melhor investir em máquina e otimizar depois, muito citam a famosa frase do Knuth1:
premature optimization is the root of all evil.
Não discordo desse “zeitgest”, é a perspectiva correta para muitos contextos, mas pode ser uma armadilha em engenharia de dados. Fluxos de processamento de dados costumam ter pouca lógica de negócio. São códigos mais breves e sofrem menos modificações, mas possuem muitos requisitos de performance e escalabilidade.
Pontos Chave
Eu nem cheguei na parte de efetivamente enviar essas mensagens em uma fila, mas acredito que já foi possível ilustrar os desafios de lidar com fluxo de dados distribuídos:
-
Não é incomum encontrar problemas que só aparecem em produção, pelas características únicas do dado e volumetria;
-
engenharia de dados é muito mais sobre os requisitos não funcionais que funcionais;
-
reproduzir um ambiente de execução distribuído é muito complexo, muitas vezes o processo é desenvolvido localmente, gerando erros que só aparecem tardiamente no processo de desenvolvimento;
-
estimar a performance em fluxo de dados é muito complexo, porque além de poder de processamento, dependem de outras variáveis como memória, disco e rede de um ambiente distribuído;
-
é importante que o engenheiro de dados tenha uma noção intuitiva do que está acontecendo internamente nas soluções, para evitar gargalos desnecessários e facilitar o troubleshoot;
-
fluxos de processamento de dados costumam ter pouca lógica de negócio. São códigos mais breves e sofrem menos modificações, mas possuem muitos requisitos de performance e escalabilidade
Nesse exemplo, nem chegamos a discutir os desafios de arquitetura da solução: por que estamos usando Spark? Haveria outra solução melhor?
Se não precisamos de escalabilidade – estamos trabalhando com uma base de tamanho constante – provavelmente seria mais simples optar por fazer um processo não distribuído usando uma infra bem dimensionada.
Utilizar soluções distribuídas desnecessariamente, poder gera situações terríveis: mais custos de desenvolvimento e operação, com soluções menos flexíveis e mais lentas que uma solução single-node.
Algumas vezes é cansativo lidar com todos essas questões, mas são problemas interessantes, é gratificante ver uma aplicação escalando bem e funcionando com a performance esperada.
-
a citação completa tem muito mais nuances: Programmers waste enormous amounts of time thinking about, or worrying about, the speed of noncritical parts of their programs, and these attempts at efficiency actually have a strong negative impact when debugging and maintenance are considered. We should forget about small efficiencies, say about 97% of the time: premature optimization is the root of all evil. Yet we should not pass up our opportunities in that critical 3%. Ao usar esses argumentos, provavelmente os programadores não estão pensando nos mesmos problema do Knuth de micro-otimizações, mas o argumento é usado de forma simplista para justificar entregas mais rápidas. ↩