O cientista que não gostava de números
O mundo corporativo é cheio de jargões e frases prontas. Alguns exemplos no contexto de dados:
“If you cannot measure it, you cannot improve it.” (Lord Kelvin)
“In God we trust; all others must bring data. (W. Edwards Deming)
Errors using inadequate data are much less than those using no data at all (Charles Babbage)
Em geral, as afirmações fazem sentido, mas frases rápidas não tratam de nuances. Ao aplicar a cultura “data driven”, vejo dois erros comuns que são pouco discutidos:
- ignorar as limitações dos dados, confiar em métricas poucos representativas;
- interpretar os dados de forma simplória, caindo em erros por análises rasas.
Quando percebo que esses problemas podem ocorrer – tenho um comportamento contra-intuitivo como cientista de dados – que é evitar trazer números. Pelo menos, tento trazê-los de forma que destaque essas limitações. Não tenho como controlar a interpretação dos resultados, mas tento destacar as limitações e pontos de atenção.
De forma alguma, quero questionar a cultura “data driven” que se criou na última década: essa é uma discussão de um problema menor, no contexto de uma mudança muito positiva. Antes errar tentando usar dados, que nem tentar.
A falsa confiança da matemática
Existe uma discussão filosófica sobre a matemática ter sido criada ou descoberta. Um argumento, a favor do segundo cenário, é sua relação com as ciências naturais1:
Se o π foi inventado para estudar o perímetro do círculo, então por que aparece na lei da distribuição normal de Gauss, um dos princípios fundamentais da estatística? O que perímetro do círculo tem a ver com estudo de populações e pesquisas de opinião?
Independente da sua opinião sobre essa discussão, a efetividade da matemática nas ciências naturais é indiscutível. E o grande sucesso das ciências naturais nos últimos séculos, gerou o efeito de “inveja da física”, em que outras áreas do conhecimento tentam replicar o uso de métodos matemáticos das ciências naturais.
Por que economistas são mais influentes que sociologistas? Justamente por utilizar muitos modelos matemáticos, a Economia parece mais próxima das ciências naturais que outras áreas de humanas. O que não significa que realmente esteja, mas mesmo sem resultados consistentes, o uso de linguagem matemática inescrutável é o suficiente para trazer credibilidade.
Modelar e representar algo matematicamente não é garantia de nada, não é somente sobre a qualidade da modelagem ou disponibilidade de dados, mas principalmente do quão bem a matemática se aplica ao problema. A questão não é a falta de capacidade dos economistas em modelar, mas a natureza do problema que estão lidando.
Preciso de um número, somente um número
Se você já respondeu a pergunta “Você recomendaria X para um amigo ou familiar?” em alguma pesquisa de satisfação, é porque a empresa adotou a metodologia Net Promoter Score (NPS). Ela foi popularizada por um artigo publicado na HBR em 2003, com o chamativo título “The One Number You Need to Grow”. A premissa era ambiciosa:
The good news is: you don’t need expensive surveys and complex statistical models. You only have to ask your customers one question: “How likely is it that you would recommend our company to a friend or colleague?” The more “promoters” your company has, the bigger its growth.
No próprio artigo, são discutidas limitações da métrica, como em cenários de monopólio ou que o consumidor não tem opções (e.g. saneamento básico, sistemas corporativos). A métrica teve uma grande adoção do mercado – surgiram estudos questionando a superioridade do NPS (1, 2) em relação às demais métricas de satisfação – mas não parece ter impactado em sua fama.
O foco não é criticar o NPS, mas ilustrar o apelo que métricas simples e ambiciosas têm. O mundo digital inundou as empresas e as nossas vidas com métricas e dados sobre tudo, mas é humanamente impossível organizar e extrair sentido sem ajuda. A “solução” é simplificar esses dados a qualquer custo e reduzir tudo a um valor mágico.
A WHOOP calculou que Cristiano Ronaldo tem 28 anos de “idade biológica”, usando sensores básicos e não invasivos das suas pulseiras, encontrados em qualquer relógio inteligente. São dados extremamente limitados que alimentam um modelo proprietário, mas que foi publicado em vários locais (1, 2, 3) como uma verdade absoluta, com o próprio atleta dizendo “The data doesn’t lie”.
Quando questiono o NPS, não é porque eu tenho uma proposta melhor ou que deveríamos abandoná-lo, a ideia é apenas ter atenção às limitações e tomar cuidado ao transformar esse tipo de métrica em KPIs e OKRs. Prever crescimento de uma empresa e avaliar satisfação do cliente – são problemas abstratos, cheio de nuances e contextual – é muito difícil que um único indicador dê conta de representar bem esses problemas.
É uma posição impopular, tanto com as áreas de negócio quanto com os parceiros da área de dados, quando eu questiono se deveríamos focar tanto em determinados números. Eu entendo a premissa de que usar um número – impreciso e/ou pouco representativo ainda é melhor que nada – mas é muito difícil apresentar um número e depois dissuadir as pessoas de confiarem cegamente nele.
Ao trazer um número e colocar vários ressalvas para utilizá-lo, as pessoas interpretam como falta de confiança. A limitação pode ser inerente ao problema, mas é algo difícil de explicar, especialmente para uma audiência menos especializada. Sempre que você titubear, haverá alguém vendendo números mágicos e muito apetite para utilizá-los.
Não é tão simples quanto parece
Um outro problema comum ao utilizar dados, é fazer leitura errada ou limitada das métricas. Uma questão sensível no Brasil, que ilustra muito bem esse problema, são discussões sobre renda.
As pessoas ficam surpresas, ao saberem que estão entre os 10% ou 5% mais ricos do país. É complicado compreender o que significa alguém ser bilionário, existir pessoas que estão 3 ordens de grandeza acima do limiar dos top 5%: esse tipo de coisa não existe em uma curva normal, nenhuma pessoa tem 200 metros de altura por exemplo. Distribuição de renda é um problema complexo de modelar, com números que fogem da nossa compreensão intuitiva sobre números.
Programadores aprenderam a olhar tempos de reposta sem assumir distribuição normal, é uma prática acompanhar percentis altos (.e.g. P95 e P99) para ter uma visão mais concreta do cenário. Mas ainda é muito difícil explicar como funciona: o tempo médio de reposta da API é 50ms, mas que não é raro ficar em 20ms ou passar de 500ms. Esses valores não encaixam na intuição de média e desvio padrão que as pessoas aprendem, tendo como perspectiva uma gaussiana.
Para lidar com dados fora da distribuição normal, é importante avaliar o cenário com boxplot, histograma e testes de normalidade. Simplesmente olhar métricas como média e desvio padrão, pensando em uma gaussiana, pode levar a uma interpretação errada da situação. Mas quantas pessoas sabem o que é um boxplot?
É fundamental que a área de negócio faça a interpretação dos dados – algo que os especialistas em dados podem e devem ajudar – mas em última instância, não é algo que pode ser completamente delegado para o time de ciência de dados.
Quando o mundo cometeu esses erros
Um cenário que exemplifica ambos os desafios, foram os modelos epidemiológicos utilizados durante a pandemia de COVID-19. Os modelos de compartimento são baseados em derivadas parciais, em que a curva de infecção é governada pela taxa \(R_{t}\): um indivíduo infecta quantas outras pessoas em um tempo \(t\) ?
Por esses modelos, lidar com a pandemia era uma questão de achatar a curva, reduzindo o \(R_{t}\) para os sistemas de saúde suportarem a demanda. Achatar a curva significava ter uma pandemia mais longa, mas com um pico de infecção menor.
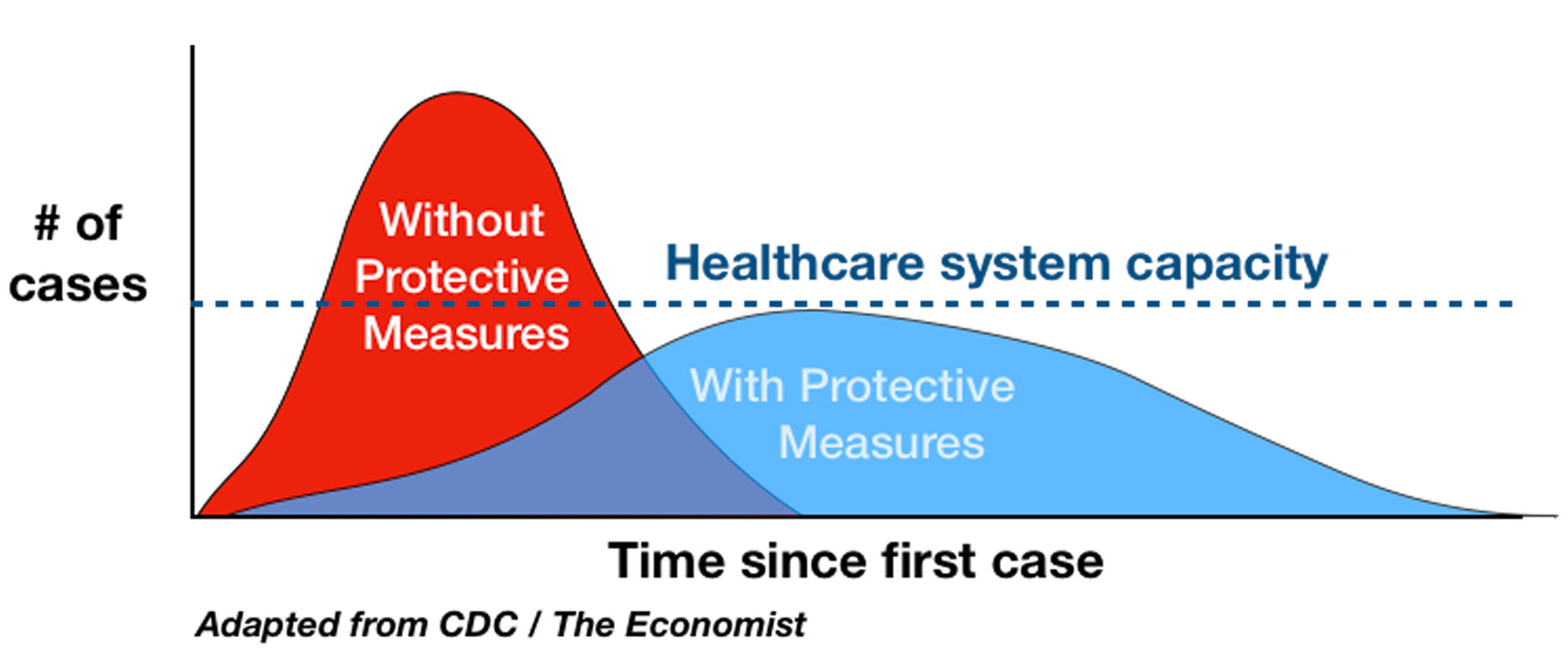
Os gráficos gerados por esses modelos foram vistos como exemplos de “storytelling” e tomada de decisão com dados , mas na prática as coisas foram diferentes. Percebeu-se que esse modelo não respondia às perguntas que a população fazia e nem serviam como preditor.
Podia-se estimar um \(R_{t}\) alvo, mas como medir esse número e como chegar nesse alvo? Percebeu-se que \(R_{t}\) era uma média, mas pessoas e contextos outliers poderiam ser o grande problema. Além disso, a nossa capacidade de diagnosticar a doença tem limitações importantes, era muito difícil saber ao certo quantas pessoas estavam infectadas em um determinado momento.
Além da dificuldade em medir o \(R_{t}\) real, o modelo de compartimentos não explicava a realidade do sistema de saúde. O mesmo \(R_{t}\) – considerando um asilo ou um vestiário de futebol profissional – traziam impactos práticos muito distintos no sistema de saúde. Outros parâmetros, como tempo de recuperação e re-infecção mudavam a todo momento: mutações do virus, tratamentos, prevenções e vacinas.
Era um cenário muito complexo, para um modelo muito simples. Uma pandemia global não é como uma doença infecciosa em ambiente natural: animais não se previnem, não fazem viagens intercontinentais, não procuram tratamentos e nem desenvolvem vacinas.
Apesar de ser impossível parametrizar os modelos corretamente em grande escala, a dinâmica geral de infecção descrita pelos modelos, ainda fazia sentido: achatar a curva era um plano, mesmo que não fosse possível estimar com precisão os parâmetros do modelo. Em contextos limitados e para projeções, esses modelos e o \(R_{t}\) eram úteis.
Ou seja, tínhamos métricas e um modelo insuficiente para lidar com a complexidade da situação. Além disso, interpretar os resultados e as implicações, era algo muito complexo para a população e tomadores de decisão.
Conclusão
Após anos de incentivo à tomada de decisão baseada em dados, talvez seja um tabu questionar seu uso. Todo modelo é uma aproximação e não uma realidade, como diria o “ditado” da estatística: todos os modelos estão errados, mas alguns são úteis.
Sou a favor de usar dados e modelos sempre que possível, mas não virar uma muleta para toda tomada de decisão. Infelizmente, nem sempre é possível trabalhar com dados, especialmente em produtos muito inovadores ou cenários em que pesquisa e testes são muito caros. É aceitar que é necessário tomar algumas decisões por convicção ou intuição, ao invés de forçar o uso de dados e modelos insuficientes.
Steve Jobs – talvez a maior referência dos “produteiros” – era famoso por não ser o maior entusiasta de pesquisas de mercado (e nem de consultores). Nenhum dashboard ou modelo, iria corroborar com a ideia de fazer um smartphone sem teclado em 2007. Muito pelo contrário, já que o produto na época era restrito ao mercado corporativo, com foco em comunicação via texto ao invés de consumo de conteúdo de hoje em dia. O valor da ideia era justamente ir contra o restante do mercado, não fazer algo incremental.
Os riscos existem: você provavelmente não tem a visão do Steve Jobs, nem os recursos da Apple e não trabalha em uma empresa com o mesmo apetite a risco. Mas forçar um número que justifique uma decisão revolucionária e arriscada, não vai mitigar seus riscos, mas pode mascará-los.
-
Se você já leu algum artigo com título no estilo The Unreasonable Effectiveness of X in Y, a origem foi um sobre essa discussão da matemática e ciências da natureza: “The Unreasonable Effectiveness of Mathematics in the Natural Sciences” ↩