O que é um arquivo parquet?
No post sobre Data Mesh, comentei sobre os trade-offs de usar uma abordagem “Unix like” para ferramentas de dados. Por um lado, é muito interessante pensando em arquitetura e estratégia, mas pode ser um problema para os usuários menos técnicos. Um exemplo desse desafio, é lidar com diferentes formatos e estratégias de serialização.
Imagino ser um cenário comum – encontrar cientistas, analistas e afins – sofrendo desnecessariamente com tabelas enormes armazenadas em formato texto (e.g. csv, json). São formatos práticos e acessíveis, ótimos para pequenos projetos, mas que não escalam bem para grandes volumes.
Uma das alternativas mais comuns para dados tabulares, é utilizar arquivos parquet. Mas o que são esses arquivos? Após anos usando parquet, tendo uma vaga noção do que se trata, surgiu a curiosidade de entender mais profundamente os detalhes de implementação.
A proposta do Parquet
O formato parquet foi proposto pelo Twitter, em parceria com a Cloudera, como um formato otimizado para uso no ecossistema Hadoop. As ideias de design por trás do formato são discutidas nessa apresentação, entre as mais importantes delas:
- encoding e compressão a nível de coluna, dando flexibilidade para otimizações;
- formato colunar, ideal para workloads analíticos;
- especificação aberta e agnóstica de plataforma.
Na especificação do formato, tem um diagrama que apresenta a estrutura geral do arquivo (Figura 1).
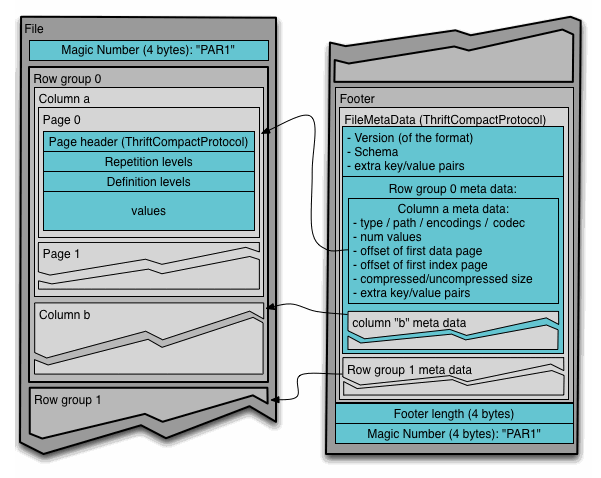
Olhando somente o diagrama, não consegui entender muito bem o formato, então optei pela estratégia de ler o código de alguma implementação. Uma ideia que acabou se mostrando bem mais complicada que o esperado, mas após muito debug e leitura de especificações, consegui entender o formato e gerar um arquivo parquet “na unha”.
Fastparquet como referência
Sendo um formato aberto, existem diversas implementações diferentes para leitura e escrita de arquivos parquet, como Arrow e Spark por exemplo. Optei pelo fastparquet, que é uma implementação puramente em Python e me permitiria debugar passo-a-passo se necessário.
Para analisar o código, fui executando linha-a-linha o comando write('outfile.parquet', df, append=False), usando a tabela abaixo.
| Key | Value |
|---|---|
| chave_1 | valor_1 |
| chave_2 | valor_2 |
| chave_3 | valor_3 |
Após executar várias vezes, consegui formar uma noção melhor da especificação. Agora, a ideia é fazer uma implementação “minimalista” em Go: transformar essa tabela em um arquivo parquet, da forma mais simples possível.
Sobre os metadados
Os metadados de um arquivo parquet são escritos usando o Thrift Compact Protocol, um tipo de serialização utilizado pelo protocolo RPC Thrift. É similar a outros protocolos de serialização, como Protobuf e Avro por exemplo.
Para quem não está familiarizado com esses protocolos, são especificações de serialização binária, otimizadas para processamento/armazenamento em comparação a formatos texto. Em contrapartida, não são amigáveis para leitura do usuário, como um json ou yaml.
Para ler e escrever em Thrift Compact Protocol, precisamos de uma especificação, um schema com a estrutura da informação. Esse arquivo é a especificação dos metadados de um arquivo parquet, uma representação gráfica da estrutura pode ser vista na figura abaixo.
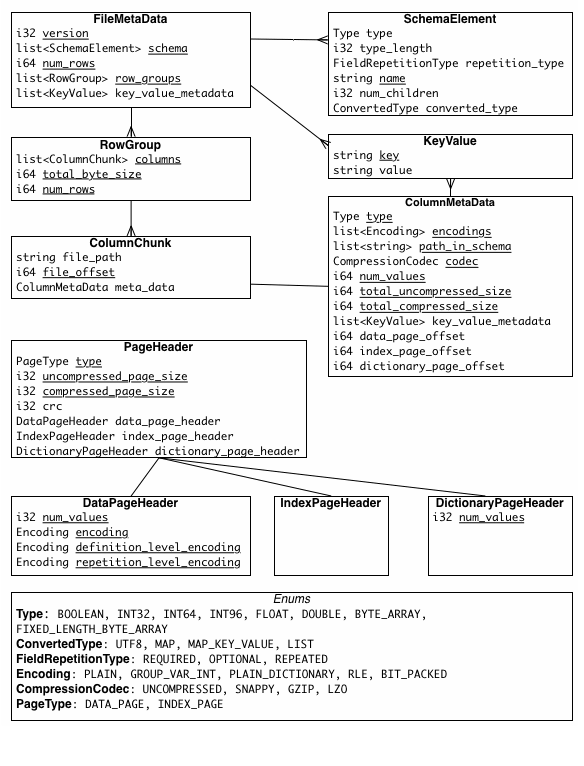
Criando uma página
A primeira parte de um arquivo parquet são as páginas de dados. Cada página contém dados de uma única coluna, uma coluna pode estar separada em várias páginas. Em nosso caso, será apenas uma página por coluna, na qual o dado será armazenado sem compactação e com representação PLAIN.
Cada página de dados tem um cabeçalho, representado pelo objetos PageHeader e DataPageHeader:
pageHeader := PageHeader{
pageType: 0 /* DATA_PAGE */,
uncompressedPageSize: int32(content.Len()),
compressedPageSize: int32(content.Len()),
dataPageHeader: DataPageHeader{
numValues: int32(len(column)),
encoding: 0 /* PLAIN */}}
Para criar esse cabeçalho, é necessário saber o tamanho da página e a quantidade de registros. Portanto, antes de escrever o cabeçalho de uma página, é necessário lidar com o conteúdo dela.
Escrevendo a coluna de strings em PLAIN text
As colunas da tabela serão tratadas como strings binárias, que podem ser representadas como BYTE_ARRAY em um arquivo parquet. Usando a representação PLAIN, basta informar o tamanho do array de bytes e escrever o conteúdo em seguida.
BYTE_ARRAY: length in 4 bytes little endian followed by the bytes contained in the array
Abaixo, o código utilizado para escrever uma coluna. Para cada item da coluna, o tamanho é calculado e representado como um inteiro em 4 bytes. O conteúdo é escrito logo após, sem nenhuma transformação.
type Parquet struct {
writer thrift.TProtocol
file io.ReadWriter
ctx context.Context
transport *thrift.StreamTransport
}
func (t *Parquet) writeColumn(records [][]byte) {
for _, record := range records {
valueSize := uint32(len(record))
size := make([]byte, 4)
binary.LittleEndian.PutUint32(size, valueSize)
t.file.Write(size)
t.file.Write(record)
}
t.transport.Flush(t.ctx)
}
Juntando no arquivo
Como é necessário saber o tamanho do conteúdo para criar o cabeçalho da página, foram usados dois buffers apartados: header e content. O content é criado antes do header, mas no arquivo é escrito na ordem inversa.
func WritePage(column [][]byte, f *os.File) int {
header := bytes.NewBuffer([]byte{})
content := bytes.NewBuffer([]byte{})
parquetHeader := TableParquet(header)
defer parquetHeader.transport.Close()
parquetContent := TableParquet(content)
defer parquetContent.transport.Close()
parquetContent.writeColumn(column)
pageHeader := PageHeader{
pageType: DATA_PAGE,
uncompressedPageSize: int32(content.Len()),
compressedPageSize: int32(content.Len()),
dataPageHeader: DataPageHeader{
numValues: int32(len(column)),
encoding: 0 /* PLAIN */}}
parquetHeader.writePageHeader(pageHeader)
pageSize := content.Len() + header.Len()
bufferToFile(header, f)
bufferToFile(content, f)
return pageSize
}
Utilizando a biblioteca em Go, a função writePageHeader escreve o objeto thrift PageHeader.
func (t *Parquet) writeI32(name string, id int16, value int32) {
t.writer.WriteFieldBegin(t.ctx, name, thrift.I32, id)
t.writer.WriteI32(t.ctx, value)
t.writer.WriteFieldEnd(t.ctx)
}
func (t *Parquet) writeDataPageHeader(dataPageHeader DataPageHeader) {
t.writer.WriteStructBegin(t.ctx, "DataPageHeader")
t.writeI32("num_values", 1, dataPageHeader.numValues)
t.writeI32("encoding", 2, dataPageHeader.encoding)
t.writeI32("definition_level_encoding", 3, dataPageHeader.definitionLevelEncoding)
t.writeI32("repetition_level_encoding", 4, dataPageHeader.repetitionLevelEncoding)
t.finishStruct()
}
func (t *Parquet) writePageHeader(pageHeader PageHeader) {
t.writer.WriteStructBegin(t.ctx, "PageHeader")
t.writeI32("type", 1, int32(pageHeader.pageType))
t.writeI32("uncompressed_page_size", 2, pageHeader.uncompressedPageSize)
t.writeI32("compressed_page_size", 3, pageHeader.compressedPageSize)
t.writer.WriteFieldBegin(t.ctx, "data_page_header", thrift.STRUCT, 5)
t.writeDataPageHeader(pageHeader.dataPageHeader)
t.writer.WriteFieldEnd(t.ctx)
t.finishStruct()
}
Ao final, a página da primeira coluna é representada da seguinte forma no arquivo.
00000000 50 41 52 31 15 00 15 42 15 42 2c 15 06 15 00 15 |PAR1...B.B,.....|
00000010 00 15 00 00 00 07 00 00 00 63 68 61 76 65 5f 31 |.........chave_1|
00000020 07 00 00 00 63 68 61 76 65 5f 32 07 00 00 00 63 |....chave_2....c|
00000030 68 61 76 65 5f 33 |have_3|
00000036
Escrevendo o rodapé
Diferente da maioria dos formatos, para ler um parquet começamos pelo rodapé. As colunas e seus tipos são especificados pelo schema, enquanto os detalhes das páginas geradas ficam nos row_groups.
Abaixo o código para escrita completa do arquivo, primeiro as páginas são geradas, para depois criar a estrutura do footer indicando a posição delas no arquivo.
f, _ := os.Create("sample.parquet")
defer f.Close()
footer := bytes.NewBuffer([]byte{})
parquetFooter := TableParquet(footer)
defer parquetFooter.transport.Close()
magicBytes(f)
sizeKeys := WritePage(keys, f)
sizeValues := WritePage(values, f)
numRows := len(records)
magicBytesOffset := 4
schema := []SchemaElement{
{name: "schema", numChildren: 2},
{name: "key", colType: 6 /*BINARY ARRAY*/},
{name: "values", colType: 6 /*BINARY ARRAY*/}}
columns := []ColumnChunk{
{fileOffset: int64(magicBytesOffset),
metaData: ColumnMetadata{
columnType: 6 /*BINARY ARRAY*/,
encodings: []int32{0},
pathInSchema: []string{"key"},
codec: 0,
numValues: int64(numRows),
totalUncompressedSize: int64(sizeKeys),
totalCompressedSize: int64(sizeKeys),
dataPageOffset: int64(magicBytesOffset),
statistics: Statistics{nullCount: 0},
},
},
{fileOffset: int64(magicBytesOffset + sizeKeys),
metaData: ColumnMetadata{
columnType: 6 /*BINARY ARRAY*/,
encodings: []int32{0},
pathInSchema: []string{"values"},
codec: 0,
numValues: int64(numRows),
totalUncompressedSize: int64(sizeValues),
totalCompressedSize: int64(sizeValues),
dataPageOffset: int64(magicBytesOffset + sizeKeys),
statistics: Statistics{nullCount: 0},
},
},
}
parquetFooter.writeFileMetadata(
FileMetaData{
version: 1,
schema: schema,
num_rows: int64(numRows),
row_groups: []RowGroup{
{columns: columns,
totalByteSize: int64(sizeKeys + sizeValues),
numRows: int64(numRows)},
},
},
)
Após escrever o footer no arquivo como um objeto Thrift, é necessário escrever o seu tamanho como um inteiro de 4 bytes. Isso é importante, porque o consumidor utiliza esse número para identificar onde o rodapé começa.
bs := make([]byte, 4)
binary.LittleEndian.PutUint32(bs, uint32(footer.Len()))
parquetFooter.file.Write(bs)
No final, o arquivo completo completo, com as duas colunas e o rodapé ficou da seguinte forma.
00000000 50 41 52 31 15 00 15 42 15 42 2c 15 06 15 00 15 |PAR1...B.B,.....|
00000010 00 15 00 00 00 07 00 00 00 63 68 61 76 65 5f 31 |.........chave_1|
00000020 07 00 00 00 63 68 61 76 65 5f 32 07 00 00 00 63 |....chave_2....c|
00000030 68 61 76 65 5f 33 15 00 15 42 15 42 2c 15 06 15 |have_3...B.B,...|
00000040 00 15 00 15 00 00 00 07 00 00 00 76 61 6c 6f 72 |...........valor|
00000050 5f 31 07 00 00 00 76 61 6c 6f 72 5f 32 07 00 00 |_1....valor_2...|
00000060 00 76 61 6c 6f 72 5f 33 15 02 19 3c 15 00 38 06 |.valor_3...<..8.|
00000070 73 63 68 65 6d 61 15 04 00 15 0c 38 03 6b 65 79 |schema.....8.key|
00000080 15 00 00 15 0c 38 06 76 61 6c 75 65 73 15 00 00 |.....8.values...|
00000090 16 06 19 1c 19 2c 26 08 1c 15 0c 19 17 00 19 18 |.....,&.........|
000000a0 03 6b 65 79 15 00 16 06 16 64 16 64 26 08 3c 36 |.key.....d.d&.<6|
000000b0 00 00 00 00 26 6c 1c 15 0c 19 17 00 19 18 06 76 |....&l.........v|
000000c0 61 6c 75 65 73 15 00 16 06 16 64 16 64 26 6c 3c |alues.....d.d&l<|
000000d0 36 00 00 00 00 16 c8 01 16 06 00 00 74 00 00 00 |6...........t...|
000000e0 50 41 52 31 |PAR1|
000000e4
No começo e no final do arquivo, temos os “magic bytes”, a constante PAR1 que identifica o arquivo como sendo um parquet.
O arquivo é mais simples que o gerado pelo fastparquet, mas não não está totalmente funcional: consegui ler com a implementação padrão em Java e Arrow, mas não usando Spark e nem o próprio fastparquet.
A implementação completa desse script está nesse arquivo.
É isso? Mais ou menos
Imagino que para resolver o problema de compatibilidade, seja necessário preencher mais metadados, que algumas implementações tratam como obrigatória. Meu objetivo era entender melhor o formato, então essa implementação capenga já atendeu seu objetivo, não animei de ir atrás de resolver essa questão.
No futuro, mais interessante que fazer uma implementação completa, seria entender os impactos de diferentes estratégias para gerar um arquivo. Um arquivo parquet – contendo os mesmos dados – pode ser gerado de diferentes formas:
-
Eu usei o encoding básico, mas estratégias de dictionary encoding e delta encoding podem fazer uma enorme diferença, além da compactação pura e simples.
-
Como funcionam o Page Index? É possível ter uma boa performance de look-up para acessos baseados em linha?
-
Qual o tamanho ideal de páginas e grupos de linha? Discute-se muito o problema de “small files” em Big Data, mas nunca vi essa discussão para a estrutura interna dos arquivos.
-
Qual as diferenças entre as várias implementações? São relevantes?
Talvez, em um post futuro, eu explore essa questão das diferentes implementações e estratégias para gerar arquivos parquet.