Criando um corpus do Skoob com Scrapy
A criação de web scrapers para gerar datasets não é a área mais descolada de ciência de dados, mas uma solução usando o Scrapy ficou tão simples e elegante, que deu vontade de escrever sobre. Neste post, vou explicar como desenvolvi um web scrapper para baixar as resenhas de livros da rede social Skoob.
Por que fazer um crawler de Skoob?
O Skoob é uma rede social para leitores, que possui um rico espaço de resenhas feitas pelos usuários da rede. No momento de escrita desse blog, encontrei mais de 600.000 resenhas para 80.000 livros diferentes.
Apesar de ser um conceito manjado – criar corpus de resenhas para análise de sentimentos – sempre é mais complicado achar esse tipo de material em língua portuguesa. Nesse contexto, achei válido desenvolver esse projetinho usando Scrapy para criar um dataset com resenhas publicadas no Skoob.
Usando o Scrapy
O Scrapy é um framework Python para extração de dados da web, lidando com o fluxo de ponta a ponta: crawling das páginas, scrapping dos dados e persistência. Ou seja, tudo o que precisamos para fazer a extração de dados do Skoob.
A parte de crawling é a etapa de navegar pelas páginas que precisam ser baixadas, de encontrar todas as URLs que precisam ser acessadas. Para o nosso projeto, essa etapa é a parte de identificar todas as URLs do Skoob que contenham resenhas de livros.
O scrapping é a parte mais trabalhosa do processo. A partir do HTML das páginas baixadas, precisamos encontrar e extrair as informações desejadas. Em nosso caso, descobrir como extrair as informações dos livros e os textos das páginas de resenhas.
Por fim, temos a etapa de persistência, que é a parte de salvar os resultados das etapas de crawling e scrapping. Salvaremos os dados em um simples arquivo JSON, mas é comum esse tipo de dado ser armazenado em algum banco de dados.
Usando o Scrapy, todas essas etapas exigiram a codificação de apenas uma classe! Nas próximas seções, irei explicar como desenvolvi esse projeto.
Instalando o Scrapy
A instalação do pacote Scrapy não poderia ser mais simples, basta um pip install scrapy, ou conda install -c conda-forge scrapycaso você esteja usando o Anaconda.
Criando um projeto Scrapy
O Scrapy é um framework e não uma biblioteca1, portanto é necessário criar um projeto com uma estrutura própria. Para tal, basta usar o comando scrapy startproject nomeprojeto, sendo nomeprojeto o nome dado para o projeto pelo usuário da aplicação, que deve ter uma estrutura similar a essa:
.
├── nomeprojeto
│ ├── __init__.py
│ ├── __pycache__
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ ├── __init__.py
│ └── __pycache__
└── scrapy.cfg
4 directories, 7 files
Criado o projeto, temos a estrutura pronta e podemos desenvolver o spider para ler e baixar as resenhas do Skoob.
Codificando o spider
Os spiders são as classes que definem quais páginas serão acessadas e como os dados serão extraídos, ou seja, estamos falando da classe responsável pelas etapas de crawling e scraping.
A estrutura básica de um Spider consiste em um método start_requests para listar as URLs que precisam ser acessadas e um método parse para extração dos dados. Usando esses dois métodos principais – criados pelo usuário – o Scrapy se responsabiliza por realizar as requisições e executar as extrações dos dados.
Vamos entender o passo-a-passo de como o spider para as resenhas do Skoob foi construído.
Encontrando os livros
O primeiro passo para fazer um processo de scrapping, é entender como estão organizadas as URLs que devem ser acessadas. As resenhas do Skoob são agrupadas por livros, portanto devemos iterar sobre todos os livros para extrair as resenhas.
No caso do Skoob, as URLs dos livros não poderiam estar organizadas de forma mais simples, já que as páginas estão indexadas por um sequencial inteiro:
skoob.com.br/livro/resenhas/1/- Resenhas de Ensaio Sobre a Cegueiraskoob.com.br/livro/resenhas/2/- Resenhas de O Caçador De Pipas- …
skoob.com.br/livro/resenhas/456920/- Resenhas de Pronto para recomeçar
Iterando de um em um nos IDs dos livros, conseguimos acesso às páginas que desejamos. Testando as URLs no browser, identifiquei que o último ID disponível era o 456.920.
A partir disso, já é possível iniciar o desenvolvimento da nossa classe ReviewsSkoob, que é uma filha da classe scrapy.Spider, dentro do diretório spiders.
class ReviewsSkoob(scrapy.Spider):
name = "reviewsSkoob"
def start_requests(self):
urls = ["https://www.skoob.com.br/livro/resenhas/" + str(i) for i in range(1, 456920)]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
O atributo name da classe é apenas uma chave para identificar o spider, usaremos ela posteriormente durante a execução do processo.
O método responsável por listar todas as URLs é o start_requests, ele deve retornar um iterável (por isso o uso do método yield) com todas as requisições que devem ser realizadas pelo Scrapy.
A partir desse lista geradas pelo método start_requests, o Scrapy conseguirá acessar todos os livros … mas não todas as resenhas.
Livros populares têm várias resenhas e, acessando apenas o primeiro link, estamos restrito a 15 resenhas. Como não sabemos a priori quantas páginas de resenha um livro tem, iremos lidar com esse problema na etapa de scraping, usando a opção de seguir links oferecido pelo framework.
Extraindo as resenhas
A estratégia de crawling já foi (parcialmente) resolvida com o método acima, agora iremos para a parte mais trabalhosa que é o scrapping das resenhas: com o DOM da página, como pegar as informações de interesse? Para essa tarefa, a única opção é inspecionar o HTML em um browser e definir que tags HTML serão extraídas.
Primeiramente, devemos definir o que desejamos extrair das páginas. Abaixo, a estrutura de dados que será extraída para cada livro:
{'author': '', # Nome do autor
'book_name': '',# Nome do livro
'reviews': []} # Lista de resenhas do livro
O atributo reviews será uma lista de objetos, que contém as informações de resenhas daquele livro. Abaixo, a estrutura desse objeto:
{'review_id': '', # Identificador único da resenha
'user_id': '', # Identificador do usuário
'rating': , # Nota da resenha
'text': ''} # Texto da resenha.
Por fim, um exemplo do resultado dessa estrutura da extração de um livro com duas resenhas.
{'author': 'Justin Herald',
'book_name': 'Atitude',
'reviews': [
{'review_id': 'resenha79081806',
'user_id': '3760854-juliana.fontes',
'rating': 4,
'text': '"Entusiasmo é bom, mas eu prefiro ter AÇÃO em minha vida."'},
{'review_id': 'resenha185981',
'user_id': '6311-andre-goeldner',
'rating': 1,
'text': 'O livro resume-se ao título. Espécie de auto-ajuda restrito à histórias pessoais vividas pelo autor. \n \nPouco acrescentador, repetitivo e desnecessário. '}]}
Definida a estrutura que desejamos, podemos agora explorar o DOM para entender como extrair essas informações.
Para identificar e extrair as informações das páginas, eu usei o Xpath, que é uma linguagem padrão para navegar em arquivos XML. Ou seja, é suportada por vários frameworks e linguagens que trabalham com dados em estrutura de XML.
A parte de extração é um pouco maçante e específica de cada scrapping, portanto não irei me estender explicando como criei as expressões Xpath, mas abaixo temos os códigos usados para a extração dos dados no método parse.
def get_user(self, user):
return user.split('/')[-1]
def get_review(self, review):
return ' '.join(review)
def parse(self, response):
self.log(f"Processing {response.url} ...")
book_info = response.xpath("//div[@id='pg-livro-menu-principal-container']")
author = book_info.xpath(".//a[contains(@href, '/autor/')]/text()").extract_first()
book_name = book_info.xpath(".//strong[@class='sidebar-titulo']/text()").extract_first()
if 'reviews' in response.meta:
reviews = response.meta['reviews']
else:
reviews = []
for review in response.xpath("//div[re:test(@id, 'resenha[0-9]+')]"):
review_id = review.xpath("./@id").extract_first()
user_id = self.get_user(review.xpath(".//a[contains(@href, '/usuario/')]/@href").extract_first())
rating = review.xpath(".//star-rating/@rate").extract_first()
text = self.get_review(response.xpath(f".//div[@id='resenhac{review_id[7:]}']/text()").extract())
self.log(f"Review {review_id} processed for {book_name}")
reviews.append({'review_id': review_id,
'user_id': user_id,
'rating': int(rating),
'text': text})
reviews_page = {
'author': author,
'book_name': book_name,
'reviews': reviews
}
O método parse é chamado para cada requisição gerada pelo método start_requests e recebe de parâmetro um objeto Response, que contém o resultado da requisição HTTP.
Perceba que eu apenas utilizo o método Response.xpath para extração dos dados dos livros e das resenhas. O uso do atributo Response.meta será discutido adiante, ele foi usado como forma de passar dados de uma requisição para outra.
Com as informações extraídas, basta usar o comando no yield no objeto criado (a variável reviews_page) para indicar que aqueles dados devem ser salvos. Entretanto, não podemos salvar os dados visitando apenas a primeira página de cada livro, pois precisamos visitar as \(N\) páginas subsequentes de livros com mais de 15 resenhas.
Neste momento, temos a maior dificuldade desse processo, que é criar uma outra requisição dentro do método parse para as demais páginas de resenhas.
Para resolver esse problema, o primeiro passo é identificar se existe uma próxima página, que pode se feito procurando pela existência de um link de próxima página:
next_page = response.css('div.proximo').xpath('.//a/@href').extract_first()
Se houver uma próxima página, precisamos criar uma requisição para a próxima página com os reviews já extraídos. Dessa forma, quando chegarmos a última página, teremos um objeto livro com todas as resenhas juntas.
Para passar essa informação para a próxima requisição, é possível adicionar a informação usando o atributo meta do objeto Request, que pode receber os dados em um estrutura de dict.
As requisições serão criadas recursivamente, sempre passando para frente os dados já extraídos, até que cheguemos a última página. A condição de parada da recursão é identificada pela presença do link de próxima página.
if next_page is not None:
request = response.follow(next_page, callback=self.parse)
request.meta['reviews'] = reviews
yield request
elif len(reviews) > 0:
self.log(f"Saving {len(reviews)} reviews for book {book_name}")
yield reviews_page
Vale notar que livros sem resenhas não são salvos no final do processo. Nesse link, temo a implementação completa dessa classe.
Agora que já resolvemos o problema de crawling e scrapping, basta executar o framework para realizar a extração dos dados.
Executando o crawler
A execução do crawler é a parte onde começamos a perceber as vantagens de usar um framework, já que o Scrapy nos oferece várias recursos interessantes “de graça”:
- Persistência automática, possibilitando o uso automático de vários formatos como JSON, CSV, XML em várias tipos de storage como S3 e FTP.
- Controle de execução via jobs, possibilitando que um processo seja pausado/reiniciado quando necessário.
- Opções de AutoThrottle para evitar sobrecarga no site do qual as informações estão sendo baixadas.
Além dessas facilidades, temos outros recursos úteis para processos de crawling e scrapping mais complexos, envolvendo questões de cookies e deploy por exemplo.
Definindo um AutoThrottle
A ideia do throttle é não onerar o site de onde estão sendo extraídas as informações, já que a ideia não é gerar um custo adicional ou indisponibilidade. Para ativar esse recurso, basta editar o arquivo settings.py na pasta raiz do projeto:
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://doc.scrapy.org/en/latest/topics/autothrottle.html
AUTOTHROTTLE_ENABLED = True
# The initial download delay
AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
A documentação do Scrapy tem uma página sobre esse assunto, detalhando o funcionamento de cada parâmetro.
Executando a extração
Para executar o crawler, basta usarmos o comando crawl do Scrapy:
scrapy crawl reviewsSkoob -o output/reviewsSkoob.json -s JOBDIR=crawls/skoob20190622
A variável reviewsSkoob é o atributo name que adicionamos na classe ReviewsSkoob. O parâmetro -o é o tipo de saída desejada para o processo, que definimos como um arquivo JSON2. Por fim, o parâmetro -s é um diretório no qual será controlado a execução do crawler, permitindo assim pausa-lo e reinicia-lo.
Agora, é só esperar o processo terminar, que ao final o arquivos reviewsSkoob.json estará com todas as resenhas.
Resultados
A execução do crawler foi iniciada no dia 22/06/2019, terminando de executar no dia 28/06/2019. Para termos dimensão da quantidade de dados, alguns métricas do corpus extraído.
- 640.644 resenhas no total.
- 81.724 livros diferentes resenhados.
- 108.882 autores de resenhas.
- 139.678.539 tokens no total.
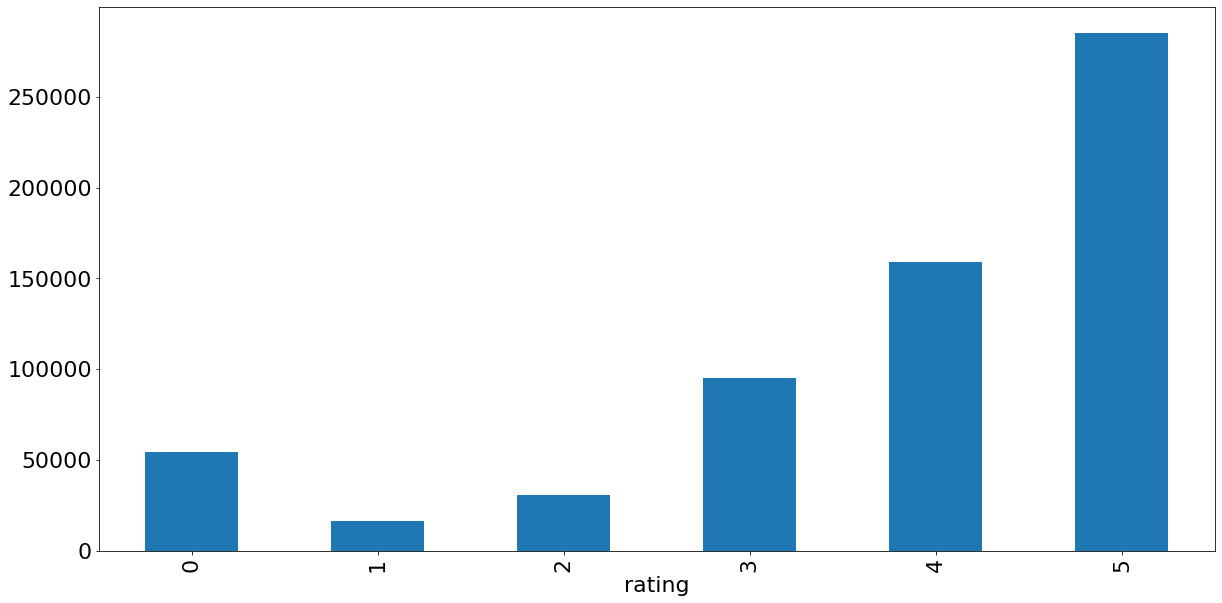
Analisando a distribuição de notas, podemos ver que as resenhas pendem fortemente para o lado positivo (Figura 1). No total, cerca de 68% das resenhas tem 4 e 5 estrelas, então estamos tratando de um dataset de resenhas com classes bem desbalanceadas.
Em relação a quais livros são mais resenhados, podemos perceber que o grande volume de resenhas está concentrado em um pequeno conjunto de livros, com uma cara de lei de Zipf (Figura 2). O Skoob exibe apenas 1.000 resenhas para cada livros, mesmo que a página indique a existência de mais, mas ainda é possível ver a grande concentração de resenhas em poucos títulos.

Em relação aos tamanhos das resenhas, se olharmos em uma escala logaritmica base 10 (Figura 3), podemos perceber que segue uma distribuição normal com \(\mu = 2,08\) (cerca de 100 palavras) e \(\sigma = 0,54\).
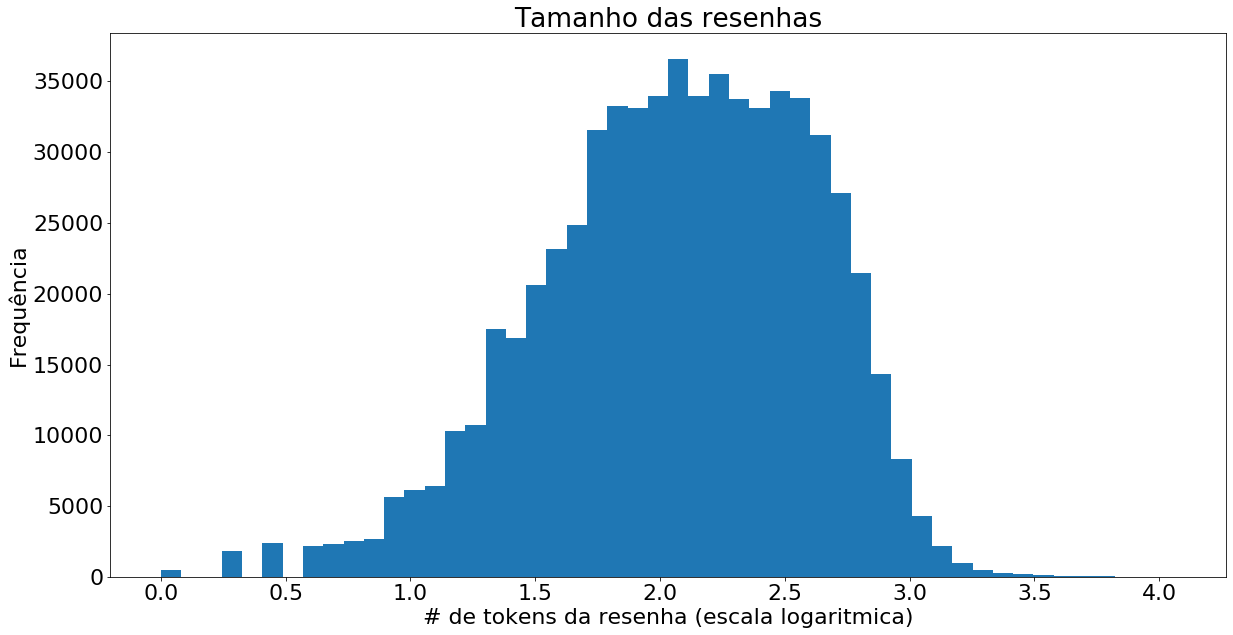
A partir dessa breve análise, podemos ver que temos aqui um grande volume de dados para se trabalhar, seja com o objetivo de compreender o comportamento dos usuários da rede social ou como insumo para treinamento de algoritmos.
O Jupyter notebook que fiz para essa análise está disponível no GitHub, assim como o restante do projeto. Caso alguém esteja interessado em trabalhar com os dados extraídos, podem me contatar por e-mail ou qualquer uma das redes sociais no rodapé da página.
Notas
-
Não existe uma única definição de framework, mas estou partindo do princípio da inversão de controle, em que o fluxo é controlado pelo framework e o código desenvolvido pelo usuário é chamado pelo framework. ↩
-
O recomendado para processos que serão pausados e reiniciados é o formato JSON Lines para evitar problemas de arquivos inválidos. ↩