Stemming com Scala
O uso de stems no lugar de palavras é uma abordagem comum para lidar com conteúdo em língua natural, dependendo da técnica utilizada, é vantajoso considerar as flexões de uma palavra como uma única dimensão. Por exemplo, em um sistema de busca, geralmente não é interessante que as palavras “amigo”, “amiga” e “amigões” sejam tratadas como chaves de busca diferentes.
Informalmente, o stem de uma palavra é similar ao radical da palavra. Para o contexto de PLN, pode-se entender o stem como a parte comum a todas as flexões da palavra. No exemplo acima, o stem do conjunto de palavras {amigo, amiga, amigões} é “amig”.
Para obter o stem das palavras, é recomendável utilizar um algoritmo desenvolvido especialmente para o idioma no qual se está trabalhando. Nesse post, mostrarei uma implementação do algoritmo RSLP desenvolvido por Moreira Orengo e Christian Huyck na linguagem Scala.
Eu implementei o RSLP anteriormente em PL/SQL como parte do meu TCC, achei divertida a ideia de reimplementa-lo em Scala usando uma abordagem funcional e, de quebra, esse código pode me ser útil em algum projeto envolvendo PLN em Spark.
O algoritmo RSLP
A ideia do algoritmo RSLP é substituir iterativamente os sufixos das palavras de acordo com uma série de regras. Abaixo, um exemplo de regra para remoção de plural:
{
"exceptions": [
"lápis",
"cais",
"mais",
"crúcis",
"biquínis",
"pois",
"depois",
"dois",
"leis"
],
"minSize": 2,
"replacement": "il",
"suffix": "is"
}
suffix: sufixo a ser removido da palavra.replacement: sufixo que deve ser adicionado após a remoção do sufixo original.minSize: tamanho mínimo do stem resultante, a regra não deve ser aplicada se o stem da palavra for menor que o tamanho definido pela regra.exceptions: palavras que são exceções a regra.
Essas regras estão agrupadas por classe gramatical, somente uma regra de cada grupo pode ser aplicada por palavra, ou seja, duas regras de plural não podem ser aplicadas em uma mesma palavra. As regras de substituição herdam outras definições de seu grupo, abaixo as propriedades das regras de plural:
"plural": {
"baseSuffixes": [
"s"
],
"fullWordException": true,
"minWordSize": 3,
"name": "plural",
baseSuffixes: sufixo que se aplica a todas as regras do grupo. Se a palavra não tiver esse sufixo, todas as regras do grupo podem ser ignoradas.fullWordException: indica se as exceções devem combinar com a palvra inteira ou apenas o final da palavra. Suponha que temos a palavra “organizado” como exceção, se esse parametro fortrue, a palavra “desorganizado” não entra como exceção. Se forfalse, “desorganizado” é removido pois “organizado” é um sufixo de “desorganizado”.minWordSize: palavras menores que esse parâmetro não devem ser avaliadas pelas regras do grupo.
Os grupos de regras devem ser aplicados na ordem correta e condicionalmente, abaixo o fluxograma de execução das regras.
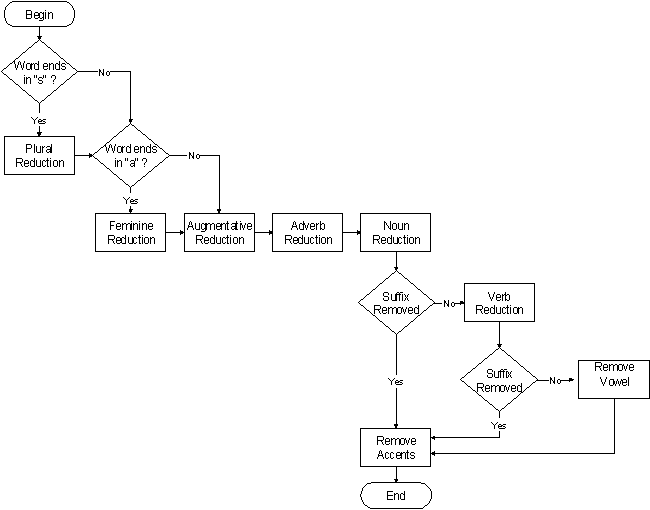
Uma discussão mais aprofundada do algoritmo, comparação com outras soluções e avaliação de resultados estão no artigo em que ele foi apresentado, assim como uma implementação original em linguagem C.
Implementando o RSLP
A ideia dessa implementação foi usar uma abordagem funcional para o algoritmo, já me desculpando pelos prováveis erros: não estudei a teoria de programação funcional, apenas aproveitei o que aprendi trabalhando com RDDs do Spark e segui regras básicas como imutabilidade dos dados e não relizar laços de forma imperativa (a.k.a sem loops).
Além de usar uma abordagem mais funcional, gostaria de utilizar um pouco de Scala fora do framework Spark. Dizem que você sempre se arrepende do seu código Scala meses depois, estou curioso para saber se esse será o caso para esse algoritmo.
Vamos ao tabalho então!
Mapeando as regras
Eu criei apenas duas classes para o algoritmo, uma classe Rule representando o grupo de regras e uma case class SuffixRule para representar cada uma das regras individuais.
As regras, da implementação original em C, estavam em um formato próprio para a aplicação, transformei em um JSON para facilitar a leitura pela minha aplicação. O JSON com as regras está dentro do projeto no GitHub, pode ser útil caso alguém também se interesse em implementar esse algoritmo.
Após a leitura do JSON, a classe Rule recebe um objeto do json4s com um grupo de regras e cria o objeto para uso na aplicação.
class Rule(json: JsonAST.JValue) {
val baseSuffixes: Array[String] = (json \ "baseSuffixes")
.children
.map(suffix => suffix.values.toString)
.toArray[String]
val fullWordException: Boolean = (json \ "fullWordException")
.asInstanceOf[JBool].value
val minWordSize: Int = (json \ "minWordSize")
.asInstanceOf[JInt].values.toInt
val name: String = (json \ "name")
.asInstanceOf[JString].values
val suffixes: List[SuffixRule] = (json \ "suffixes")
.children
.map(suffixInfo => {
SuffixRule((suffixInfo \ "minSize").asInstanceOf[JInt].values.toInt,
(suffixInfo \ "replacement").asInstanceOf[JString].values,
(suffixInfo \ "suffix").asInstanceOf[JString].values,
(suffixInfo \ "exceptions").children.map(_.asInstanceOf[JString].values).toSet[String])
Mapeando o fluxo principal
A minha primeira opção para executar o fluxograma de regras foi criar um objeto Rule para cada grupo de regras e ir chamando os objetos sequencialmente, mas não gostei dessa solução. Seria necessário armazenar cada stem intermediário em uma variável mutável ou criar uma variável para cada etapa do stemming, ficando com cara de linguição.
A solução alternativa foi armazenar as regras em um vetor, na ordem correta de execução, e implementar as condicionais em uma função recursiva.
@tailrec
def applyRules(word: String, rules: Array[Rule], step: Int) : String = {
if (step >= rules.length) return removeAccents(word)
val rule = rules(step)
val (ruleApplied, stem) = rule.evaluate(word)
if (rule.name == Rules.noun && ruleApplied) {
return removeAccents(stem)
}
if (rule.name == Rules.verb && ruleApplied) {
return removeAccents(stem)
}
applyRules(stem, rules, step + 1)
}
Apesar do fluxo principal conter 4 condicionais, somente os 2 últimos alteram o fluxo de aplicação de regras. O método Rule.evaluate retorna o stem resultante da aplicação do grupo de regras e um booleano indicando se houve modificação na palavra, essas duas informações são suficientes para controlar o fluxo de execução.
O método removeAccents, chamado ao final do método applyRules, troca os caracteres acentuados das palavras. O método foi implementado usando o interessante recurso de pattern matching do Scala: para cada caracter acentuado, é retornado o correspondente sem acentuação, caso contrário retorna-se o próprio caracter.
def removeAccents(word: String): String = {
word map {
case 'á' => 'a'
case 'ã' => 'a'
case 'â' => 'a'
case 'é' => 'e'
case 'ê' => 'e'
case 'í' => 'i'
case 'î' => 'i'
case 'ó' => 'o'
case 'õ' => 'o'
case 'ô' => 'o'
case 'ú' => 'u'
case 'û' => 'u'
case c: Char => c
}
}
Aplicando o grupo de regras
O método Rule.evaluate executa toda a lógica do grupo de regras, três condições são avaliadas:
- Verifica-se se a palavra tem o tamanho mínimo para aplicação do grupo de regras (1).
- Se houver sufixos básicos para o grupo de regras, é verificado se a palavra o contém (2).
- Por fim, as regras do grupo são verificada individualmente (3).
def evaluate(word: String) : (Boolean, String) = {
if (word.length < minWordSize) return (false, word)
if (baseSuffixes.nonEmpty) {
val matchedSuffixCount = baseSuffixes
.count(suffix => word.endsWith(suffix))
if (matchedSuffixCount == 0) return (false, word)
}
val stem = suffixes
.filter(evaluateSuffixRule(word, _))
.map(suffixRule => word.dropRight(suffixRule.suffix.length) + suffixRule.replacement)
if (stem.nonEmpty) (true, stem.head)
else (false, word)
}
No passo (2) e (3) não achei nenhuma forma de indicar que o filtro é mutuamente exclusivo, ou seja, que temos no máximo uma regra elegível dentro do grupo. Com essa informação, um método filter alternativo poderia executar menos validações desnecessárias parando a execução ao encontrar a primeira regra elegível.
Avaliando e aplicando as regras de stemming
O método para avaliação das regras individuais é o mais oneroso e também o mais executado durante o processo de stemming, abaixo a implementação do método Rule.evaluateSuffixRule:
def evaluateSuffixRule(word: String, suffixRule: SuffixRule): Boolean = {
val validSuffix = word.endsWith(suffixRule.suffix)
val stemLength = word.length - suffixRule.suffix.length + suffixRule.replacement.length > suffixRule.minSize
if (validSuffix && stemLength){
if (fullWordException) {
! suffixRule.exceptions.contains(word)
} else {
! suffixRule.exceptions.exists(exception => word.endsWith(exception))
}
} else {
false
}
}
A implementação atual é bem ingênua, as regras são avaliadas uma a uma. Caso a regra seja validada em relação ao sufixo e ao tamanho, é feita uma busca na lista de exceções que, no pior caso, é varrida por completo para regras nas quais apenas o sufixo da palavra é o suficiente para configurar uma exceção.
Em várias etapas do processo de stemming, uma busca por sufixo é realizada. Usando uma árvore de sufixos, teríamos ganho de performance (em termos de complexidade) para tarefas relativamente custosas do algoritmo:
-
Sufixos da regra: armazenando os sufixos das regras em uma árvore de sufixos, eles poderiam ser recuperados em tempo quase constante (proporcional a quantidade de caracteres da palavra), não sendo mais necessário verificar regra a regra individualmente.
-
Lista de exceções: a lista de exceções também poderia ser uma árvore de sufixos, tornando o tempo quase constante para o pior caso, regras em que apenas o sufixo das exceções devem coincidir com a palavra para configurar uma exceção.
Os sufixos base das regras também poderiam ser armazenados em uma estrutura de sufixos, entrento a maior lista contém apenas dois sufixos, tornando desnecessário armazena-las em uma estrutura complexa como uma árvore de sufixos.
Conclusão
Implementar o algoritmo RSLP é um exercício divertido, sendo uma lista de regras pré-determinadas é natural implementa-lo usando uma abordagem funcional. Além do exercício, sendo um algoritmo exclusivo para português, é interessante saber implementa-lo pois é possível que não esteja disponível para a plataforma na qual se está trabalhando.
A implementação completa desse algoritmo está disponível no GitHub.